Z shell (Zsh) has been my shell of choice in both Linux and macOS. I used to install oh-my-zsh or the claimed-to-be-faster Prezto or Zim to leverage some of their cool libraries.
Unfortunately, I realised that my favourite terminal app, iTerm 2, became more and more sluggish when loading a new tab or window with more than one and a half second (without some virtual environment loaders like nvm, rvm, rbenv, jenv).
A quick G-fu could yield numerous posts on how to debug, optimise, speed up Zsh. I spent some time to refactor my own lightweight scripts instead of using big frameworks and was able to reach nearly one third of a second. In this post, I will share and discuss some aspects that might affect Zsh loading time and how to mitigate them. Most of the relevant code and configurations can be found here.
TL;DR:There are many aspects in Zsh that can potentially slow down its startup time and can be mitigated.
Performance Analysis
Overall execution time
Crunching some numbers on Zsh loading time would be definitely useful for further in depth analysis of its performance. A simple timing of Zsh startup time can be measured approximately using the time command that is available in most Unix/Linux/Mac systems.
$ /usr/bin/time /bin/zsh -i -c exit
0.67 real 0.41 user 0.26 sys
The output of the command shows the execution time of Zsh breaking down to user-land and system. In order to get a better approximation, we can make a loop that invokes time for 10 or greater, if possible.
for i in $(seq 1 10); do /usr/bin/time /bin/zsh -i -c exit; done;
This timing method is very fast and handy in case you want to quickly see how your Zsh performs, especially to test some changes you have just made.
Profiling
Zsh provides a built-in module zsh/zprof that can be used to profile Zsh functions. At the beginning of ~/.zshrc, we add zmodload zsh/zprof. After restart the shell, we can use the command zprof to show a very rich output on Zsh startup loading. An illustrative output of zprof is shown below.
$ zprof
num calls time self name
------------------------------------------------------------------------------
1) 1 51.31 51.31 22.68% 49.68 49.68 21.96% zle-line-init
2) 2 45.72 22.86 20.21% 45.72 22.86 20.21% compaudit
3) 195 34.71 0.18 15.34% 25.52 0.13 11.28% _zsh_autosuggest_bind_widget
...
Note
Two aforementioned approaches can give us a rough analysis on what aspects are invoked during Zsh startup so that we might figure out the bottleneck. In case you need to dig deeper, Arnout wrote a nice article in which he suggested a in-depth analysis and visualisation of Zsh loading using
xtraceandkcachegrind. Benjamin developed a similar approach to more thorough tracing and analysis Zsh execution.
Problematic Aspects and Mitigation
Using two simple methods mentioned above, I was able to roughly understand some issues of my Zsh settings and tried to mitigate them to reduce startup time. I could not report the exact steps what have been done as it was a lot of trial-and-errors. Here I will discuss some major aspects combining my actual experiment and G-fu research.
Organising shell startup order
The order that Zsh loads its configuration files are documented here and here. Peter Ward drew a nice diagram showing the loading process of Zsh alongside with Bash and Sh (note that he omitted the system-wide configurations in Zsh part).
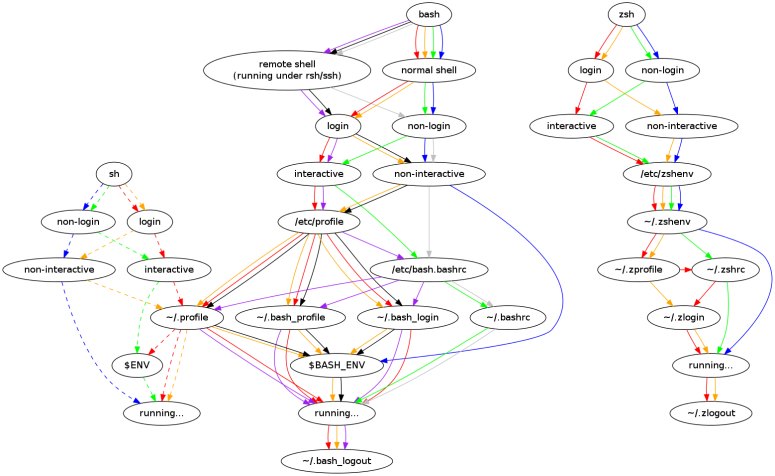
It’s also useful to understand relevant shell concepts, such as login vs. non-login, interactive vs. non-interactive shown in the diagram. Please refer to, for example, here or here for further explanations.
Some shell examples:
- when opening a terminal emulator app (e.g. Terminal or iTerm 2), we are creating an interactive, non-login shell (please see
login -pflater).- when logging in into a machine using command line
sshorsu - username, we are working with an interactive login shell.- when executing a shell script, it is on a non-interactive, non-login shell.
Grokking Zsh startup order will help us putting relevant configurations in right files as well as optimising the loading process. My local Zsh setting is orgranised as follow:
.zshenv: invoked by all invocations of Zsh, so we should keep it small and merely initialise necessary variables..zlogin: will be loaded in login shells after .zshrc. My .zlogin will compilezcompdumpin background as this is time-consuming and done only once per log-in session..zprofile: similar to .zlogin but will be sourced before .zshrc. Note that, both .zprofile and .zshrc are skipped in non-login non-interactive shells, as shown in Figure 1. So I learned a trick from Prezto that declares environment variables in .zprofile and uses .zshenv to source .zprofile (e.g. .zprofile and .zshenv). This way, non-login non-interactive shells will receive proper variable initialisations..zshrc: will be sourced in interactive shells. This contains the main part of Zsh configuration (e.g. my .zshrc).
Avoiding creating subprocesses
Some commands look totally innocent and standard in your shell scripts but might cost you dearly. Among them are commands that launch new child processes such as command substitutions and eval commands.
Command Substitutions
In Zsh, a command enclosed in $(command) or quoted with backticks `command` will be replaced with its standard output. Thus, it is very popular in Unix/Linux world when one wants to execute a command and get the output to process further on. The bad thing is that command substitution will launch a new process (i.e. a subshell).
eval command
eval [arg...]
The command eval (sounds with evil, ^_O) is part of POSIX standard and is available in most shells. It’s often used together with command substitution. Essentially, eval concats its arguments separated with spaces along with evaluating any variables or expressions to form a command with or without arguments. Then it executes the resulting command in the current shell. As such, eval will cause side-effects as it must evaluate the inputs and perform expansions, if any.
$ command="print 'Hello World'"
$ command # nothing happen
$ eval $command
Hello World
This feature makes eval powerful as it can dynamically evaluate and execute code. But dynamic evaluation also makes eval risky and time-consuming.
In some cases, for instance, simple string manipulation, we can consider to replace command substitutions and eval commands that invoke sed, awk, etc., with Zsh built-in constructs or hard-coded constants. Zsh provides numerous powerful built-in mechanisms for substring matchings, string explosion/splitting, and expansions.
For instance, when using Homebrew, it is very convenient to get the path to an installed package using $(brew --prefix <package>).
export PATH=$PATH:"$(brew --prefix httpd)/bin"
It turns out many calls to $(brew --prefix ...) would launch many subprocesses and thus slow down Zsh notably. When replacing that $() command with its actual output, I could gain certain improvement. The caveat is that some upgraded versions might break these hard-coded values.
Lazy-loading instead of eager-loading
Function autoloading
We can define and source new functions in Zsh. In this way, a function is eagerly loaded and always available for use. Note that most of these functions might be not really needed until being invoked.
Zsh can help postponing their loading time and allow to load-on-demand via function autoloading. This technique is often called lazy loading. Performance-wise, lazy loading will put less pressure to the underlying system and reduce memory footprint. The same techniques are also preferred in many other fields such as databases, dynamic runtime libraries, etc.
In my codebase, I create a folder, namely, autoloaded, to store functions that will be, er…, autoloaded by Zsh. For each function, for instance, function hello(){...}, I will create a corresponding file named hello inside autoloaded. The content of that file is the function body (i.e. without function and (){}).
$ mkdir autoloaded
$ echo "print 'Hello World'" >> autoloaded/hello
$ tree
.
└── autoloaded
└── hello
The folder autoloaded must be added to ZSH variable fpath where ZSH will look for function definitions.
# add 'autoload' to fpath
$ fpath=($fpath autoloaded)
# try to invoke 'hello'
$ hello
zsh: command not found: hello
# now mark `hello` for autoloading.
$ autoload hello
# quickly check how `hello` will be loaded.
$ which hello
hello () {
# undefined
builtin autoload -X
}
# now it works fine
$ hello
Hello World
The body of hello was marked with #undefined along with builtin autoload -X meaning it will be loaded on-demand. The first time hello is called, Zsh will automatically load and execute it.
In the same way, I configured Zsh to load all of my functions on-demand to reduce memory and loading time.
Note:In my scripts,
autoload -Uz function_namewas used. The option-Uprevents alias from being expanded. That is, whenever you define an alias and a function having the same name, the alias will be considered first instead, so-Ujust skips alias expansion. And the option-zindicates that the function will be auto-loaded usingzshorkshstyle.
Selective- or lazy-loading virtual environments
Many virtual environment loaders like rvm, rbenv, jenv, nvm have been developed to manage different run-time versions and libraries. While being very handy for software development, most of these tools need to be eagerly loaded (e.g. directly source in .zshrc) to work properly.
Instead, we can consider to transform these loaders as much as possible into on-demand wrapper functions. You can find a good example here. In summary, Peter’s trick is to override nvm with his own autoloaded nvm() (that eventually invokes the original nvm loader). Carlos also went to same way for rbenv, his own antibody, pyenv and achieved some good results. Benny C. Wong did similarly for both nvm and rvm.
You can also find another interesting post by Frederic about optimising Zsh loading time by converting Kubernetes’s initialisation code into a lazy-loading function. When not using lazy-loading, you might find Adam’s trick useful for reducing rbenv time.
Optimising completion system
One of the beloved Zsh’s features is its new completion system, so-called zshcompsys. That is, when you type half of a certain command and press Tab, Zsh is able to show some suggestions for completing that command.
Zsh does ship with some built-in support for popular commands but not for all kinds of commands. Instead, Zsh offers powerful means for defining custom completion via underscored-autoloaded files.
Zsh completion system must be activated by calling function compinit. Most of the framework like oh-my-zsh or Prezto will take care of initialising completion system. In my case, after getting rid of big frameworks, I have to manually activate it with autoload -Uz compinit && compinit.
Every time compinit is invoked, it often checks its configurations and re-generates in case of changes. Some have investigated this matter and suggested improvements such as checking compinit’s cache only once a day. A similar approach has also been implemented in Prezto.
Here is a simple excerpt based on Carlos’s solution.
autoload -Uz compinit
if [ $(date +'%j') != $(/usr/bin/stat -f '%Sm' -t '%j' ${ZDOTDIR:-$HOME}/.zcompdump) ]; then
compinit
else
compinit -C
fi
Lessening compinit invocations
When running zprof to profile Zsh execution, as many others also found out, I noticed a lot of invocations to compinit. It was because I used some smart plugins like zsh-users/zsh-completions and zsh-users/zsh-autosuggestions and scattered compinit in many places. Using ack, I could quickly spot and remove all compinit, then only call once at the end of my .zshrc.
Compiling completion dumped files
Note that by default compinit will produce a dumped configuration for accelerating future access. The default dumped file is .zcompdump (which can be changed with compinit -d new_dump_file or totally disabled with compinit -D).
We can go further by compiling the dumped file with the built-in command zcompile for faster autoloading of completion functions. As completion is only needed for interactive shell sessions, I put the zcompile code inside .zlogin and force it to run in background mode.
# Execute code in the background to not affect the current session
{
# Compile zcompdump, if modified, to increase startup speed.
zcompdump="${ZDOTDIR:-$HOME}/.zcompdump"
if [[ -s "$zcompdump" && (! -s "${zcompdump}.zwc" || "$zcompdump" -nt "${zcompdump}.zwc") ]]; then
zcompile "$zcompdump"
fi
} &!
Optimising shell prompts
You can find a lot of frameworks or plugins offer super duper cool command line prompts like this, this, or these that show rich information regarding your current working folder such as versioning status, virtual environments, and many more.
Obviously getting these information will induce extra execution time, especially for checking large versioned repositories or virtual runtime libraries. That leads to many workarounds, tweaks, hacks, other hacks, and more hacks.
You might want to consider some recent approaches on speeding up shell prompts such as Anish’s non-blocking prompt or Sindre Sorhus’s pure based on Mathias Fredriksson’s zsh-async. I have tried pure and found out its timing is very close to my own prompts based on vanilla Zsh scripts and built-in function vcs_info. Therefore, I mostly switch back and forth between these prompts in my dev box and totally satisfy with their performance thus far.
MacOS-specific optimisations
Optimising path_helper
In the chain of Zsh startup order, /etc/zprofile will be sourced before ~/.zprofile. So, macOS uses /etc/profile to establish paths to executable files via path_helper.
$ cat /etc/zprofile
# system-wide environment settings for zsh(1)
if [ -x /usr/libexec/path_helper ]; then
eval `/usr/libexec/path_helper -s`
fi
To do that, path_helper will read /etc/paths and /etc/manpaths, then read all files inside /etc/paths.d and /etc/manpaths.d and append their contents to $PATH and $MANPATH, respectively. New paths can be conveniently added by adding a plaintext file in /etc/paths.d instead of messing common shared configuration files.
Previously in some cases, path_helper might be very slow as mentioned by Michael Tsai here and even deserved a patch and a Perl based alternative. I reckoned that path_helper is getting notably slow when the number of paths are growing but its recent version is no longer a script but 64-bit binary executable and seems to work faster.
If you notice that path_helper makes Zsh slow, you can just put the contents of /etc/paths and of all files in /etc/paths.d directly in .zprofile . After that, just comment out the corresponding code in /etc/profile.
Optimising the login process
The default login process of macOS could be the culprit too. Opening a terminal window or tab will trigger login -pf username which, in turn, reads from and writes into the logs file in /var/log/asl (note syslog() invocations in login.c).
We can check this out in any terminal app. The command ps -ef | grep login will show details about the login process.
$ ps -ef | grep login
...
0 25142 25141 0 6:40AM ttys000 0:00.13 login -fp htr3n
In case you want to dig deeper, execute the following command in a terminal tab/window,
$ sudo opensnoop | grep "/var/log/asl"
then open another tab or window to see a lot of accessing to ASLs (standing for Apple System Log, deprecated since macOS 10.12 but still in use somewhere).
Thus, some have reported a magic that somehow speeds up shell startup by deleting macOS ASLs.
# remove all Apple system logs -- more destructive way
$ sudo rm -rf /private/var/log/asl/*.asl
Nevertheless, these logs will continuously grow day after day. We might configure /etc/asl.conf to permanently reduce the amount of ASLs. Using sudo to open that file in Text Editor (or your editor of choice),
$ sudo open -e /etc/asl.conf
then looking for the following lines and changing them accordingly and leaving the rest intact.
...
# save everything from emergency to notice
# ? [<= Level notice] store
? [<= Level critical] store
...
The idea is to change the log level from notice to a higher level such as warning, error, or critical (see more on Syslog Message Severities in RFC 5424. You might also look further in the folder /etc/asl/ to tinker log configurations of certain applications but that is beyond the scope of this article.
Another way is to skip the process of accessing ASLs altogether. For instance, with iTerm 2, press ⌘ + , to open menu , then go to .
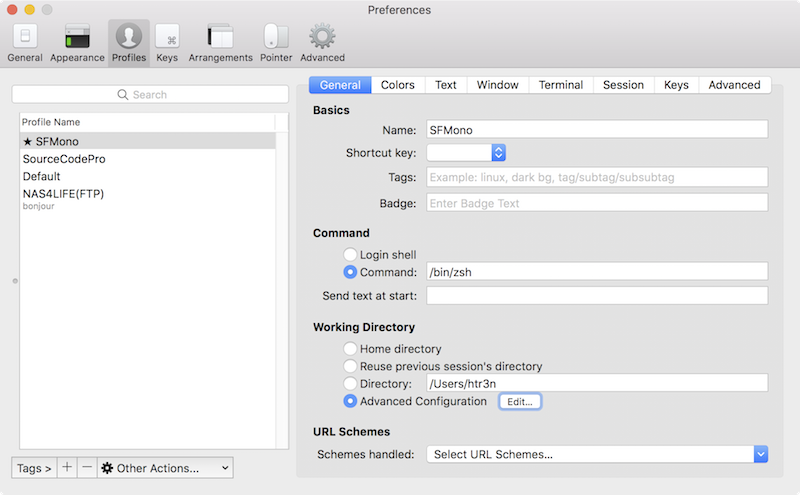
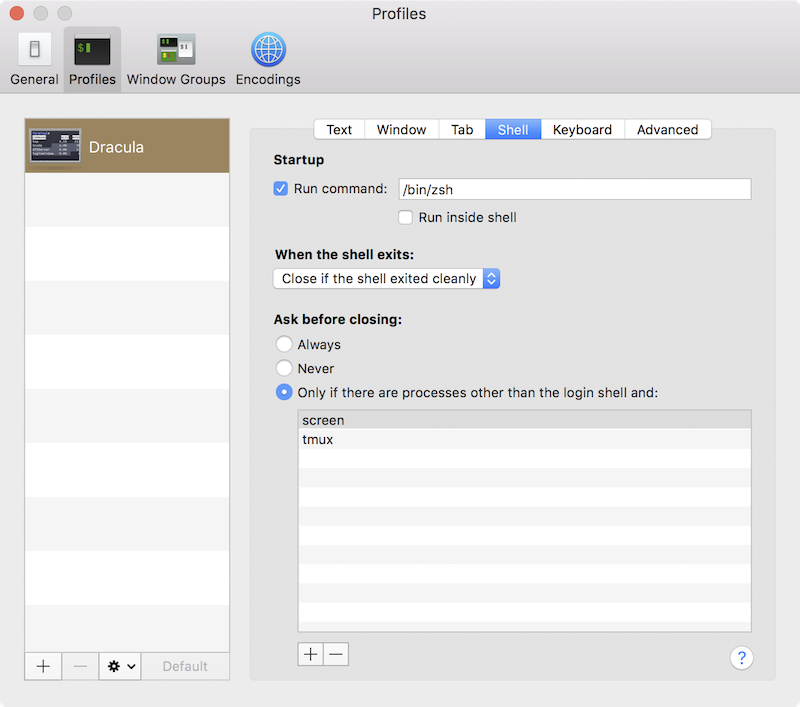
The same way can be applied for Apple’s built-in Terminal app.
Conclusion
We have walked through some major aspects that might affect Zsh in particular, and other shells, loading time. I hope these discussions can help you to pinpoint and address your shell startup issues and have better experience working with shells and command line. This is what I got after all these effort.
❯ for i in $(seq 1 5); do /usr/bin/time /bin/zsh -i -c exit; done
0.31 real 0.16 user 0.13 sys
0.28 real 0.15 user 0.12 sys
0.28 real 0.15 user 0.12 sys
0.28 real 0.15 user 0.12 sys
0.28 real 0.15 user 0.12 sys
If you have any suggestions for improvement or successful tweaks, please drop a comment below.
Reading List
- https://kev.inburke.com/kevin/profiling-zsh-startup-time
- https://esham.io/2018/02/zsh-profiling
- https://carlosbecker.com/posts/speeding-up-zsh
- https://github.com/robbyrussell/oh-my-zsh/issues/5327
- https://coderwall.com/p/sladaq/faster-zsh-in-large-git-repository
- https://ahmadnazir.github.io/posts/2016-11-03-load-shell-faster/post.html
- https://superuser.com/a/47856/82870
- https://github.com/robbyrussell/oh-my-zsh
- https://github.com/sorin-ionescu/prezto